Le di un cerebro a la empresa
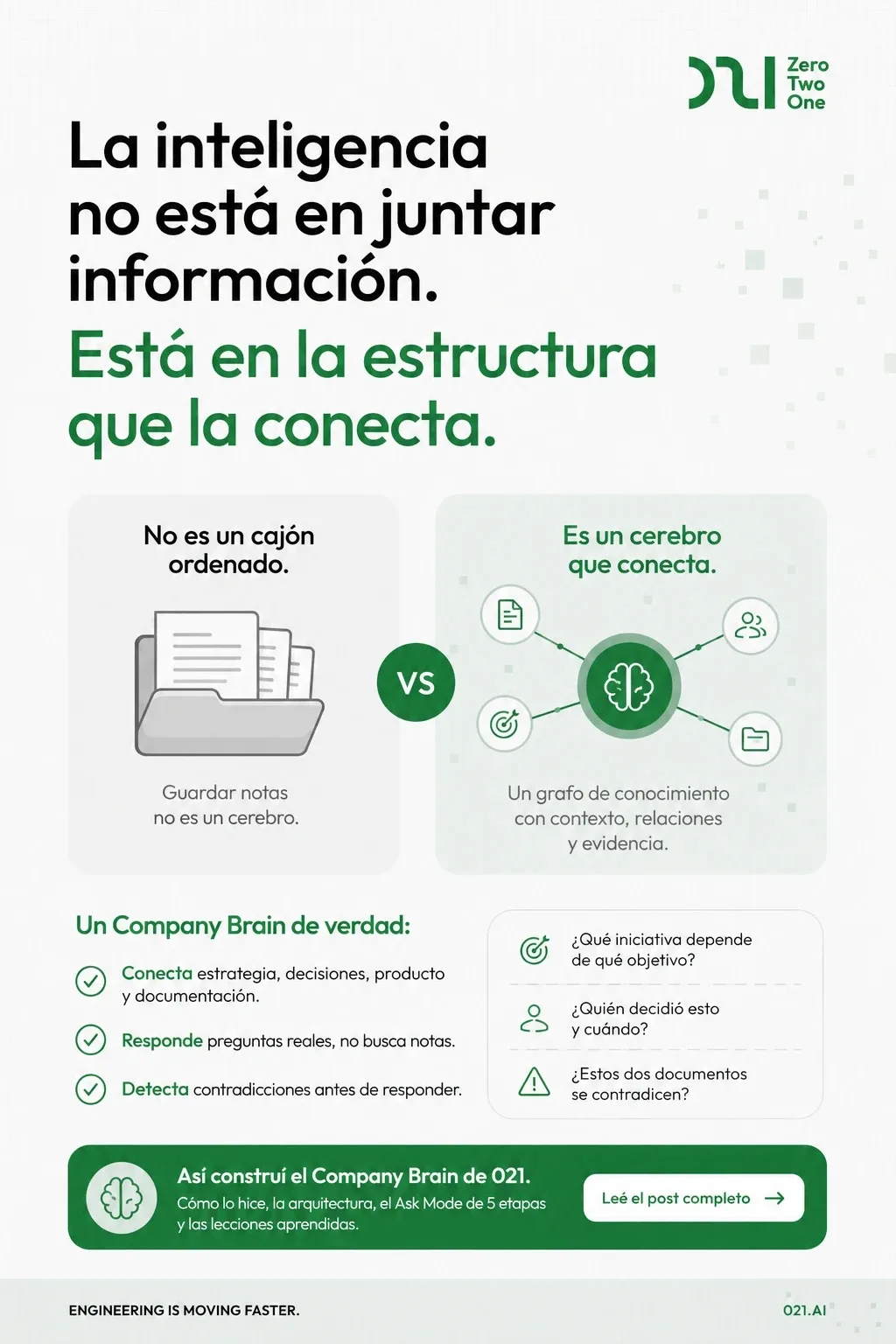
El RAG vectorial responde "¿qué se parece a esto?", pero no "¿qué depende de qué?", "¿quién lo dijo?" ni "¿esto se contradice?". El Company Brain de 021 usa un grafo híbrido en Neo4j — capa documental con embeddings + capa semántica de entidades y relaciones — donde cada afirmación apunta a su evidencia exacta, y responde con una máquina de estados de cinco etapas que detecta contradicciones antes de contestar.
En 021 construimos el Company Brain: un sistema que se traga todos los documentos de una organización —estrategia, producto, decisiones, docs técnicos— y responde preguntas sobre ellos. La parte interesante no es que funcione. Es por quéfunciona — y por qué la respuesta no fue "metele RAG".

El problema: la empresa sabe, pero no puede recordar
Toda organización acumula conocimiento en miles de documentos: el PRD de hace ocho meses, el OKR del trimestre, la decisión técnica que alguien escribió en un Confluence y nadie volvió a abrir. El conocimiento existe, pero está desconectado. Nadie puede preguntar "¿cómo se relaciona esta iniciativa con nuestros objetivos?" y obtener una respuesta con fuentes.
La tentación es obvia: RAG vectorial. Cortás los docs en pedazos, generás embeddings, y cuando alguien pregunta, traés los chunks más parecidos y se los pasás a un LLM. Funciona para una demo. En serio, no.
Por qué el RAG puro no alcanza
El vector search responde una sola pregunta: "¿qué se parece a esto?". Eso es útil para "encontrame algo sobre onboarding". Es inútil para las preguntas que la gente realmente hace:
- "¿Qué depende de qué?" — relaciones, no similitud. El vector no sabe que el OKR necesita la capability que construye el equipo.
- "¿Quién dijo esto y cuándo?" — procedencia. Un chunk suelto no te dice de qué doc salió ni si sigue vigente.
- "¿Esto se contradice con aquello?" — conflictos. Dos chunks parecidos pueden decir cosas opuestas, y el RAG te los entrega a los dos sin avisar.
La conclusión a la que llegamos es la misma que aplicamos en todo lo que hacemos con agentes: el conocimiento útil no sale de tirar vectores, sale de estructura.
La estructura: un grafo híbrido, no una pila de chunks
El Company Brain guarda el conocimiento en dos capas sobre un grafo (Neo4j), no en un índice plano de vectores:
- Capa documental.Organización → Archivo → Versión → Chunks (con sus embeddings). Esto da el "buscar similar" clásico — pero anclado a su origen.
- Capa semántica. Entidades (objetivos, capabilities, equipos, decisiones) conectadas por relaciones reales:
OWNS,NEEDS,CONTRIBUTES_TO. Esto responde el "qué depende de qué".
Y la pieza que lo cierra: cada entidad y cada relación apunta de vuelta a su evidencia — el archivo, el chunk, el fragmento de texto exacto y un score de confianza. Nada flota sin fuente. Cuando el sistema afirma algo, puede mostrar de dónde lo sacó. (Si leíste mi post sobre la proyección electoral, es la misma obsesión: un agente sin fuente de verdad alucina.)
Cómo entra el conocimiento: ingesta en dos tiempos
Subir un documento no es "guardarlo". Es procesarlo. Lo partimos en dos fases para que la subida sea instantánea y el trabajo pesado pase después:
- Pre-cola (sincrónico, <1s). Valida, deduplica por hash, convierte los formatos simples a Markdown canónico, guarda el blob y los metadatos, y encola el trabajo. Devuelve un
job_idal toque. - Post-cola (asincrónico). Un worker hace el enriquecimiento real: traduce PDFs/Word a Markdown, clasifica el doc, lo resume, lo chunkea, genera embeddings, y —lo importante— extrae entidades y relacionesy las resuelve contra el grafo existente (¿esta "iniciativa X" es la misma que ya tengo, o una nueva?).
Un detalle que nos ahorró dolor: Markdown canónico como fuente de verdad. En vez de inventar un JSON distinto por cada tipo de archivo, todo se normaliza a Markdown antes de enriquecer. Un solo formato interno, un solo pipeline.
Cómo sale: Ask Mode, agentes que no son magia
Acá está la parte que conecta con todo lo que escribo. Cuando alguien pregunta algo, nohay un agente mágico que "piensa" y responde. Hay una máquina de estados determinística de cinco etapas, cada una trazable:
pregunta
↓
[ARQUITECTO] descompone la pregunta en tareas
↓
[ROUTER] asigna cada tarea a un worker (grafo / vector / KB)
↓
[FAN-OUT] ejecuta las tareas en paralelo
↓
[AUDITOR] deduplica hallazgos, detecta contradicciones
↓
[ESTRATEGA] sintetiza la respuesta final, con evidenciaCada etapa es un agente con un trabajo chico y verificable. El auditores la pieza clave: antes de responder, busca activamente findings que se contradicen y los marca. Un RAG normal te junta todo y reza; este sistema te dice "ojo, estos dos documentos no coinciden".
¿Por qué determinístico y no un agente suelto? Por lo mismo que en mi workflow prefiero clones aislados y loops de E2E verificables: un proceso con etapas claras se puede trazar, auditar y arreglar. Un agente que decide todo solo se puede, a lo sumo, rezar.
Lo que lo hace portable: puertos y adaptadores
Todo lo de afuera —la base de datos, el grafo, el blob storage, la cola, los embeddings— está detrás de interfaces (puertos). En local corre con disco, MySQL y Neo4j en Docker; en producción, con Vercel Blob, Upstash y Neo4j cloud. El mismo código, sin tocar una línea de lógica. Eso es lo que hace que un agente pueda desarrollar contra una copia local sin depender de servicios reales.
La lección, otra vez
Es el mismo patrón que se repite en todo lo que construyo: aislar, dar fuente de verdad, hacer cada paso verificable. Cambia el dominio —workspaces, proyecciones electorales, el conocimiento de una empresa entera— pero la receta no.
Construimos cosas así en 021. Si estás peleando con RAG que "casi" funciona, o armando algo parecido, escribime — esas conversaciones son las mejores.